Market Context
The artificial intelligence market crossed a structural threshold in 2026. There are now more than 47,400 publicly listed AI tools, growing by hundreds each week. Worldwide AI spending is projected to exceed $2 trillion, and 21% of the global adult population reports using AI tools daily, according to KPMG. Yet behind these numbers sits a quieter, more uncomfortable statistic: 95% of corporate AI pilot projects fail to deliver measurable ROI.
47,400+ AI tools listed (2026) | 95% of AI pilots fail to ROI | $460 avg SMB monthly AI spend | 37% time saved per worker |
The gap between adoption and outcome is not a technology problem. It is a selection problem. Most decision-makers are not failing to find AI tools , they are failing to choose the right ones.
The Search Era
For most of the past three years, finding an AI tool has been a search task. A buyer with a problem types a query - "best AI for video editing," "AI tool for legal contracts," "top AI for customer support" - and works through results.
This works in theory. In practice, the search era produces three predictable failure modes:
• Affiliate noise. A growing share of "top 10 AI tools" pages are ranked by who pays the highest affiliate commission, not by tool quality.
• Recency bias. Search engines surface the newest content, which favors tools with the loudest marketing budget rather than the strongest track record.
• Category confusion. Queries like "AI for marketing" return 40+ tools spanning copywriting, SEO, ad generation, social scheduling, and analytics - categories that should not be compared as one.
Decision-makers are spending more time evaluating AI tools than they did three years ago, even as the tools themselves get easier to test. The bottleneck has moved from access to discernment.
Hidden Costs
Selecting the wrong AI tool is not a free mistake. The full cost extends across three dimensions:
Direct cost
Mid-sized businesses spend roughly $460 per month on AI tools, and enterprise teams average $4,100 per month, according to industry research. Cancelling and reprocuring inside the first 90 days frequently triggers refund disputes, prorated charges, and re-onboarding cycles.
Time cost
Knowledge workers spend an estimated 2.5 hours per day searching for and switching between information sources. Choosing a tool that does not fit the team's workflow adds to that load rather than reducing it.
Opportunity cost
42% of AI startups fail because they built solutions for problems that did not actually exist. The mirror image is true on the buyer side: organizations that select tools by hype rather than by fit-for-purpose end up paying for capabilities they never use.
"The bottleneck has shifted from finding AI to choosing AI. Discovery is no longer the hard problem. Selection is." - FirmCritics editorial team |
The Shift Underway
A measurable transition is happening across how decision-makers approach AI procurement in 2026. Three signals indicate the shift:
• Procurement teams are taking over AI tool decisions. Up from individual buyers in 2024, most enterprises now require finance and IT sign-off for AI subscriptions above $50 per month per user.
• Trial-then-buy is becoming the default. Buyers expect free trials with full feature parity, not feature-gated demos. Vendors who refuse are skipped.
• Review aggregation is replacing single-source reviews. Decision-makers triangulate G2, Capterra, Trustpilot, Reddit, and YouTube creator reviews before purchasing.
The underlying behavior change is simple: buyers no longer trust search engine rankings as a substitute for evaluation. The decision lifecycle has expanded from search → buy to search → evaluate → validate → buy. Each new step needs a different kind of information source.
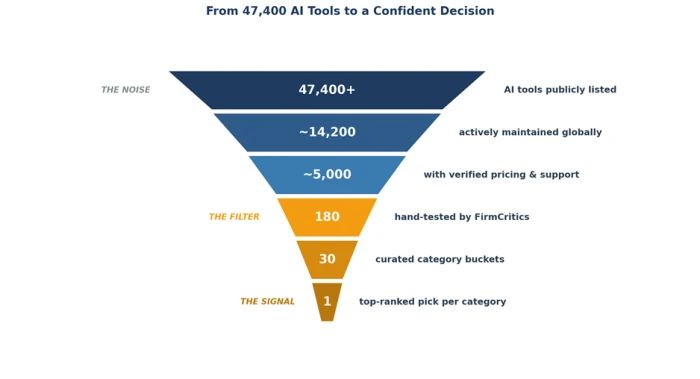
Selection Mindset
Selection is not the opposite of search. It is the layer on top of it. A selection mindset accepts that finding candidates is easy and that the difficulty lies in three downstream tasks:
• Verification. Confirming a tool actually does what its marketing claims.
• Comparison. Ranking candidates against the dimensions that matter for the specific use case.
• Fit assessment. Determining whether the tool fits the team, the budget, and the existing tech stack.
A search-first approach answers "what exists?" A selection-first approach answers "what should be bought, by whom, for what purpose, at what price?" The two questions look similar. The answers are different categories of information.
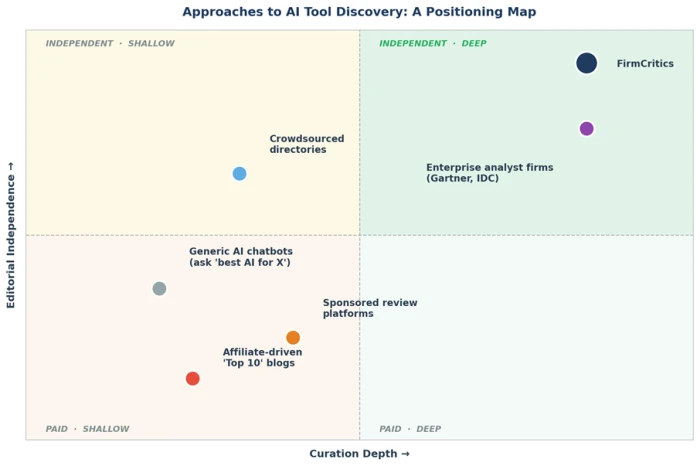
Reading the map: Most AI tool discovery resources sit in the lower or upper-left quadrants - fast and free, but shallow or affiliate-influenced. Only two categories occupy the upper right: enterprise analyst firms, which cost tens of thousands of dollars per report, and independent curation platforms like FirmCritics.
Evaluation Anatomy
A useful evaluation contains evidence, not opinions. The table below outlines twelve of the twenty-five criteria FirmCritics uses to score every tool in its directory. The full criteria set covers output quality through pricing transparency to long-term support reliability.
| Criterion | Question Asked | Evidence Required |
|---|---|---|
| Output quality | How good is the work product? | Output samples across edge cases |
| Speed and reliability | How fast and consistent is it? | Latency tests, uptime reports |
| Pricing transparency | Are costs clear and predictable? | Public pricing page, no quote walls |
| Onboarding | Time-to-first-value | First useful output under 10 minutes |
| Free credits / trial | Can it be tested before payment? | Free tier or refundable trial |
| Integration breadth | Does it fit existing stack? | Native connectors, API access |
| Support responsiveness | What happens when things go wrong? | Response time benchmarks |
| Privacy clarity | How is user data handled? | Published privacy policy, training opt-out |
| Watermark / branding | Does output carry vendor branding? | Clean output on free tier |
| API limits | Will scaling break the workflow? | Rate limits, throughput caps |
| Content moderation | How does the tool handle edge cases? | Refusal patterns, false positives |
| Hidden costs | Are there add-ons or credit traps? | Total cost of ownership |
Why this matters: A tool can score high on marketing and low on three or four of these criteria simultaneously. Without a structured rubric, those failure modes stay invisible until after purchase.
The FirmCritics Method
FirmCritics applies a consistent eight-step methodology to every tool that enters its directory. The approach is built on two principles: hands-on testing by real editors, and cross-source sentiment aggregation from independent community channels.
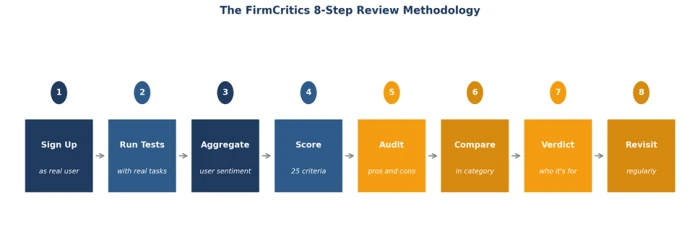
Step-by-step breakdown
• Step 1 - Sign up as a real user. Editors purchase the same plan a buyer would, on the same devices, at the same price. No comped enterprise demos.
• Step 2 - Run real tasks. Tools are tested against representative workflows, including the edge cases where most products quietly fail.
• Step 3 - Aggregate community sentiment. Reviews are pulled from Trustpilot, Reddit, Discord, app stores, and independent creator content.
• Step 4 - Score against 25 criteria. Each criterion receives a 1–10 score backed by specific evidence, not impressions.
• Step 5 - Audit pros and cons. Both sides are documented openly, including what vendors would prefer to hide.
• Step 6 - Compare within category. Every tool is ranked head-to-head against direct competitors in its category.
• Step 7 - Issue a verdict. Each review ends with a clear statement of who should buy and who should look elsewhere.
• Step 8 - Revisit regularly. Top picks are re-tested. When a tool changes significantly, the review is updated and dated.
Scoring Architecture
The 25-criteria framework is organized into five weighted groups. Each criterion is scored on a 1–10 scale and contributes to a composite score that appears in the directory header.
| Criterion Group | Weight | Coverage |
|---|---|---|
| Product Quality | 8 criteria | Output, speed, accuracy, edge cases, reliability |
| Commercial Clarity | 5 criteria | Pricing, hidden costs, free tier, refund policy, terms |
| User Experience | 5 criteria | Onboarding, UI, documentation, mobile parity, accessibility |
| Trust and Privacy | 4 criteria | Data handling, training opt-out, certifications, retention |
| Support and Updates | 3 criteria | Response time, channels, update cadence |
Practical impact: Two tools with the same composite score can have very different criterion profiles. A 7.4 driven by strong output but weak support tells a different buying story than a 7.4 driven by mediocre output but excellent privacy practices. Detailed criterion breakdowns make those distinctions visible.
Sentiment Layer
Hands-on testing reveals how a tool works for an editor. Community sentiment reveals how it works at scale. Both perspectives are needed because a great solo experience can mask problems that only show up in production use.
| Source | Type of Signal | What It Surfaces |
|---|---|---|
| Trustpilot | Verified consumer reviews | Billing complaints, refund issues |
| Unfiltered user threads | Quality regressions, account problems | |
| G2 and Capterra | Verified business buyer reviews | Enterprise fit, integration depth |
| YouTube creators | Demonstration walkthroughs | Workflow realism, output quality |
| Discord communities | Real-time vendor and user interaction | Bug reports, support responsiveness |
| App stores | Mobile user reviews | Crashes, missing features, paywall traps |
The aggregation principle: When editor testing and community sentiment agree, confidence is high. When they disagree, the review documents both signals openly. Decision-makers see the disagreement rather than being shown only the conclusion.
Category Intelligence
Tools cannot be compared in the abstract. A video generator and an AI chatbot have nothing in common beyond the "AI" label. FirmCritics organizes its directory into 30+ categories, each with its own set of category-specific criteria layered over the universal 25.
| Category | Primary Use | What Matters Most |
|---|---|---|
| Image Generator | Static visual creation | Output quality, style range, commercial use rights |
| Video Generator | Motion and video clips | Frame coherence, audio sync, output length |
| Content Generator | Long-form text | Voice consistency, factual reliability, edit-ability |
| Music Generator | Audio composition | Genre range, copyright clarity, vocal options |
| AI Chatbot | Conversational interaction | Reasoning depth, context window, persona fidelity |
| AI Agents | Autonomous task execution | Multi-step success rate, error handling, tool use |
| AI Website Builder | Site generation | Template quality, customization, hosting included |
| AI Personal Assistant | General productivity | Task variety, integrations, mobile parity |
Why categorization matters: Generic "top AI tool" rankings are misleading because they aggregate across incompatible use cases. Category-first ranking aligns the comparison with the actual buying decision being made.
Decision Maker Profiles
Different roles weigh selection criteria differently. The table below maps eight common decision-maker profiles to their primary priorities and the specific signals each role uses to evaluate AI tools.
| Decision Maker Role | Primary Priority | Key Selection Signals |
|---|---|---|
| Solo founder | Cost-efficient single-purpose tools | Free tiers, flat pricing, no per-seat math |
| Marketing manager | Output quality at scale | Tone control, brand voice consistency, integrations |
| Engineering lead | Reliability and API access | Uptime, rate limits, documentation depth |
| Operations director | Workflow automation and predictability | Total cost of ownership, support SLA, audit logs |
| Finance and procurement | Risk and contractual clarity | Pricing transparency, data residency, exit terms |
| Chief technology officer | Strategic fit across stack | Security posture, ecosystem direction, vendor stability |
| Small business owner | Quick wins with minimal setup | Time-to-value, mobile parity, customer support quality |
| Educator or tutor | Reliable, citation-grounded output | Privacy posture, content moderation, free-tier access |
Buyer Checklist
Before purchasing any AI tool, decision-makers should be able to answer yes to the items below. The checklist is short on purpose. Most failed AI purchases stem from skipping items 1, 3, and 7.
✓ The tool's category has been clearly defined and matched to the actual use case.
✓ A free trial or refundable test period has been used to verify output quality.
✓ Pricing has been read on the vendor's pricing page, not summarized by a third party.
✓ Hidden costs (credit metering, per-seat scaling, API overages) have been quantified.
✓ At least two independent review sources have been checked.
✓ Community sentiment has been spot-checked on Reddit or Trustpilot.
✓ Privacy posture, including training data policy, has been verified.
✓ The total cost of ownership over 12 months has been calculated.
✓ A backup or alternative has been identified in case the tool fails.
✓ A specific success metric has been defined before purchase.
Practical note: A decision-maker who applies this checklist to ten candidate tools per year saves between 20 and 60 hours of evaluation time annually, compared to ad-hoc evaluation. The largest gains come from items 1 and 7, where most search-era buyers cut corners.
Closing Outlook
The AI software market has crossed the point where finding tools is no longer the hard problem. The hard problem is selecting tools that fit. As 47,400+ options become 60,000+, then 100,000+, the value of structured, independent evaluation only increases.
Decision-makers who treat AI procurement like consumer software - read the marketing page, sign up, hope for the best will continue to land in the 95% of pilots that fail. Decision-makers who adopt a selection framework, lean on independent curation, and validate against community sentiment will land in the 5% that deliver measurable returns.
The shift from search to selection is already underway. Platforms like FirmCritics make it operational by providing the structured evaluation, category intelligence, and community signal aggregation that buyers need to navigate a market that has outgrown ad-hoc discovery.
Comments
Join the discussion and share your perspective.