The review promised the tool would save me ten hours a week. Three weeks in, I had saved exactly zero. I was still wiring it into my inbox and rewatching the setup walkthrough, then quietly redoing about half of what it spat out.
That was the moment something clicked. The review I had trusted was honest about what the tool could do. It said nothing about what the tool would actually do once the novelty wore off and I had real work sitting in front of me.
This piece is the writeup I wish someone had handed me back then. I want to walk you through the gaps that almost every AI review leaves open, and the simple lens I now run every tool through before I hand over a credit card. By the end you will have a checklist you can hold up against any review, plus a clearer sense of why the flashiest tool is rarely the one worth keeping.
Why honest reviews still mislead you
Reviewers are not lying to you. The format is the problem.
A reviewer usually gets a few hours with a new tool. The company hands over a clean demo and the one use case that shows the product at its best. Readers click on excitement, not caution. Put those incentives together and you get a highlight reel, beautifully shot, with every missed attempt left on the cutting-room floor.
A highlight reel is not a forecast.
So the question worth asking is the one the highlight reel skips: what does this tool do consistently, and at what real cost, once nobody is performing for the camera? I spent a year and too much money learning to answer that. What follows is the shortcut I built so you can skip the expensive part.
The lens I use now: R.E.A.L.
After the third tool that looked brilliant in a review and then gathered dust in my account, I stopped reading reviews for the verdict and started reading them for evidence. I built a four-part lens, and I run every candidate through it before the free-trial clock even starts.
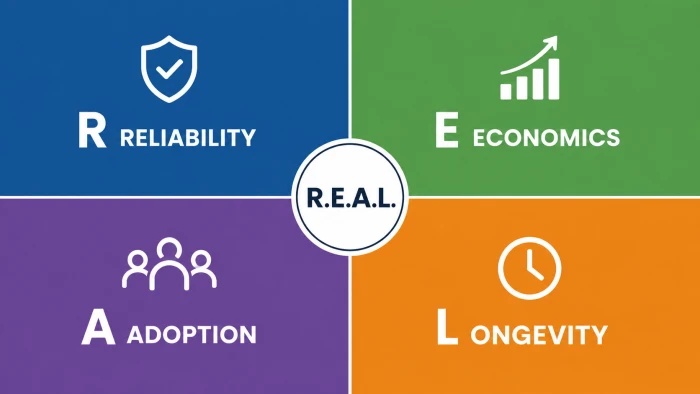
I call it R.E.A.L.: Reliability, Economics, Adoption, Longevity. The next four sections take them one at a time, and each one is built around a question a review almost never bothers to answer. We will pull all four back together when we reach the checklist near the end.
Reliability: can it do that again?
The review that sold me my first tool showed three gorgeous outputs in a row. What it did not show was the fifteen mediocre ones the reviewer churned through to land those three. That is the trick hiding inside most AI demos. You see the wins. You never see the hit rate behind them.
Reliability is the boring question that actually predicts your day. Out of ten honest attempts, how many come out usable without heavy fixing? A tool that dazzles one time in five will frustrate you the other four.
Benchmarks deserve the same suspicion. A model that tops a public leaderboard has proven it does well on a test designed in a lab. It has proven nothing about your messy inbox or the deadline already sitting on your desk. I have watched tools with lower benchmark scores quietly outperform their flashier rivals on the only test that counts, which is the work I actually needed done.
Every failed attempt also carries a price, and that points straight at the next piece of the lens.
Economics: the price tag is the smallest number
The monthly price is the cheapest part of any tool. It is also the only number most reviews bother to quote.
Here is what the “$20 a month” headline tends to hide the moment you are past the trial:
- Premium models locked behind a higher tier than the one the reviewer was using
- API charges that begin the instant you automate anything
- A separate seat for every teammate who logs in
- Usage caps and automation credits you burn through by mid-month
- Onboarding hours nobody invoices and everybody pays for
Add those up and a tool reviewed as a $20 toy becomes a $300 line item for a five-person team. The honest figure is the total cost of ownership, not the sticker.
There is a second cost: reviews almost never put a number on, and it surprised me most. AI rarely deletes work. It relocates it. I stopped writing first drafts and started inspecting them, hunting for the one confident factual error buried inside an otherwise clean paragraph. My job had quietly shifted from author to editor.
That shift sounds like a win until you have lived it for a month. Editing a draft that is wrong in subtle, plausible ways can take longer than writing from scratch, because first you have to notice that it is wrong at all. Count that supervision time as part of the price. It never shows up in the review, and it always shows up in your week.
All of this assumes your team actually opens the tool. Plenty of teams never do, which is the dimension I am turning to next.
Adoption: power nobody uses is worthless
A tool can ship with a hundred features and still lose to a plainer one that lives where you already work. Most people use a small handful of features and ignore the rest. What decides whether a tool sticks is whether it slides into the apps your team already opens every morning, or whether it asks them to wander somewhere new every time.
Power means nothing if nobody touches it.
In the previous section I treated supervision as a cost. Adoption decides whether that cost gets shared across a team or lands entirely on you, the one person who bothered to learn the thing. A tool dies on two predictable things: friction, and people’s reasonable attachment to a routine that already works. Remove those and even a modest tool starts earning its keep.
The reviews I trust now spend more words on integrations than on feature counts. A calendar that talks to the calendar you already keep, or a writing tool that lives inside the editor you already type in, beats a standalone wonder that makes everyone copy and paste between tabs all day. The dull, well-connected tool wins the only race that matters, the one measured in daily use.
Say your team does adopt it and builds real habits around it. The question that decides the next year is whether you could ever walk away.
Longevity: easy to enter, hard to leave
Getting in is easy by design. Every tool builds a wide, welcoming front door. Getting out is the part the review skips entirely.
By the time you want to leave, you may be tangled in proprietary file formats, automations you reshaped your whole week around, data trapped inside a structure with no clean export, and a team that would need retraining on whatever comes next. Ask the exit question before you sign, not after the switching cost has quietly grown into a wall.
There is a slower risk too. Models change under you. The platform a reviewer praised in January can swap its underlying model in June, and suddenly your tuned prompts behave differently while the outputs you relied on start to drift. You changed nothing. The ground moved.
A review is a photograph of one week. You are buying a moving target, and the picture goes stale the moment the next model update ships.
There is one factor that none of these four dimensions fully captures, and in my experience it decides more than the other four combined. I will get to it right after I hand you the tools to put this lens to work.
A checklist to hold against any review
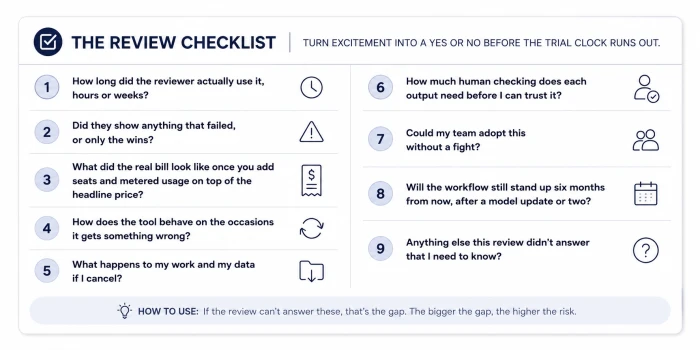
Here is how I turn that four-part lens into a yes or a no before the trial clock runs out. The next time a review gets you excited, run it through these questions and pay close attention to the ones it simply cannot answer:
- How long did the reviewer actually use it, hours or weeks?
- Did they show anything that failed, or only the wins?
- What did the real bill look like once you add seats and metered usage on top of the headline price?
- How does the tool behave on the occasions it gets something wrong?
- What happens to my work and my data if I cancel?
- How much human checking does each output need before I can trust it?
- Could my team adopt this without a fight?
- Will the workflow still stand up six months from now, after a model update or two?
Every one of these aims at something the original review left out. That gap is the whole subject of this article, and the checklist is just a way of dragging the gap into the light.
What a review should measure instead
If I could rewrite the scorecard reviewers reach for, I would swap every vanity metric for the thing it is quietly standing in for. The table below is the trade I would make:
| What reviews count | What actually decides value |
|---|---|
| Number of features | Hours saved after setup is done |
| Benchmark scores | Real business outcomes |
| Headline monthly price | Total cost of ownership |
| Polish of the demo | Consistency across many attempts |
| Automation claims | Human effort still required |
The left column is what sells a review. The right column is what you will feel six months later.
The factor no tool can fix: your own skill
Here is the factor sitting underneath all four dimensions, the one no review ever scores. It is the person using the tool.
The strongest AI users I know were already strong at the very thing they are now automating. A marketer who understands positioning gets far more out of a copywriting tool than a beginner does, because the marketer can tell sharp copy apart from plausible filler. The beginner ships the filler. The same gap shows up in engineering and in finance, anywhere a confident wrong answer carries a real cost.
This is the part I had backwards at the start. I treated AI as a way to skip the learning. It works far better as a multiplier on the learning you already have. It raises your ceiling faster than it patches your gaps, which means the smartest investment standing next to any tool is still your own judgment.
So before the next glowing review talks you into a trial, hold it up against the four questions and watch closely for what the reviewer left out. The tool worth paying for is the one that still earns its place the week after the demo ends, when nobody is performing and the only thing left in the room is the work.
Comments
Join the discussion and share your perspective.