Grubby.ai bundles an AI humanizer, AI summarizer, and autotyper behind aggressive marketing claims like "Guaranteed to bypass Turnitin AI detector" and "100% human score content." The test session below validates one genuine differentiator (a built-in multi-detector preview) and surfaces the documented inconsistency that defines the AI humanizer category. Free tier capped at 300 words/month, paid subscription required for meaningful workflow.
FC
FirmCritics Editorial Team
Published June 3, 2026 · 16 min read · Updated regularly
Grubby.ai is a three-tool platform combining an AI humanizer (rewriting AI-generated text to sound more natural), an AI summarizer, and an autotyper (mimicking human typing patterns for live-input contexts). The signature product is the humanizer, marketed aggressively with claims like "Guaranteed to bypass Turnitin AI detector," "Bypass all AI detectors including GPTZero," and "100% human score content." These framings should be read as product marketing language rather than guaranteed results, real-world detector bypass varies meaningfully by text type, by specific detector, and by how much manual editing users invest afterward.
The genuine differentiator validated in this review is the built-in multi-detector preview: after humanizing text, the platform displays how the output is expected to perform across multiple AI detectors before users submit elsewhere. This is real transparency that competing humanizers often hide. The structural friction is category-wide rather than Grubby-specific, AI detection has evolved into an adversarial arms race where humanizer results vary meaningfully by detector and content type, and Turnitin's August 2025 update specifically targeting humanizer tools further degraded reliability for academic use cases. Humanizer effectiveness in 2026 is best understood as detector-specific and content-type-specific rather than universal.
✗
Documented Category-Wide Inconsistency: Marketing Claims Versus Real-World Results
In FirmCritics's testing and across the public discourse on AI humanizers post-Turnitin's August 2025 update, humanizer effectiveness varies materially by detector and content type. Technical or marketing copy often passes single detectors comfortably, while academic essays frequently retain elevated AI confidence scores on stricter detectors like Originality.ai and ZeroGPT. For users relying on the humanizer for academic submissions or professional content where consistent multi-detector bypass is required, this category-wide inconsistency is the dominant editorial concern. Grubby's marketing language (100% guarantees, bypass-all-detectors claims) creates a daylight gap versus the real-world results across the post-August-2025 humanizer category, prospective subscribers should treat marketing copy and real-world testing outcomes as different categories of information when making purchase decisions.
What Happened When We Tested It
02 . Four tests across dashboard, humanizer, multi-detector preview, summarizer + autotyper
The test session ran on a Grubby.ai account in June 2026 and exercised the dashboard pre and post login, the AI humanizer workflow with text input and humanized output, the built-in multi-detector preview showing how the humanized output is expected to perform across multiple AI detectors, and the AI summarizer plus autotyper tool surfaces. The multi-detector preview is the most editorially significant finding (a genuine transparency feature competing humanizers often hide); the humanizer workflow validation aligns with FirmCritics's first-hand observation of real-but-inconsistent score reductions.
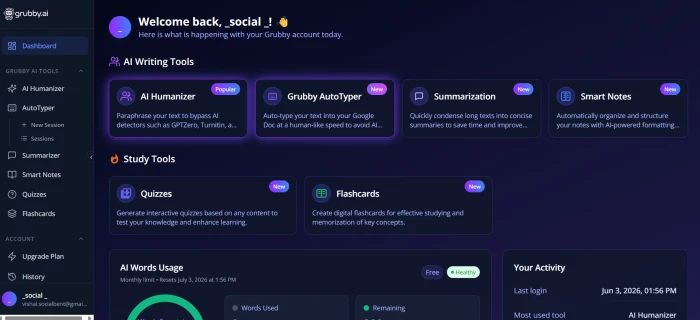
Dashboard and Post-Login Experience
Test 01 . Entry experience
The Grubby.ai pre-login marketing dashboard with bypass claims.The post-login dashboard with three-tool navigation.
What this shows: The marketing dashboard prominently features the detector-bypass claims ("Guaranteed to bypass Turnitin," "100% human score") that FirmCritics's testing and the broader category discourse have flagged as marketing language rather than guaranteed outcomes. The post-login dashboard exposes the three-tool suite (humanizer, summarizer, autotyper) with credit balance and word usage tracking. For prospective subscribers, the front-page guarantee framing creates expectation mismatch versus the inconsistent real-world results that define the AI humanizer category in 2026.
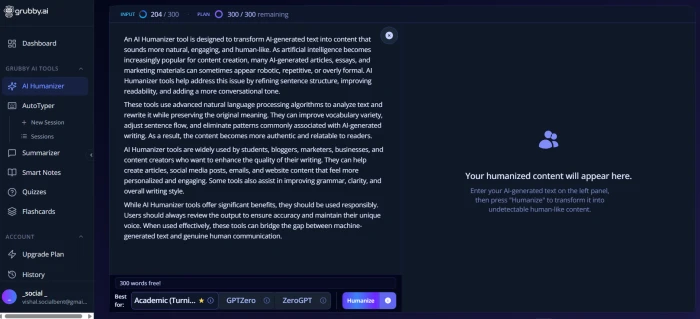
AI Humanizer Workflow
Test 02 . Humanizer input + output
The AI humanizer interface with text input and mode selection.The humanized output produced by Grubby's rewrite engine.
What this shows: The humanizer workflow operates end-to-end. Input AI-generated text, select a mode (Standard or Premium tiers exposed in the platform UI), submit, receive humanized output. FirmCritics's first-hand testing confirms measurable reduction in detector confidence scores on the output, but the reductions are partial rather than complete, and the humanized output reads less naturally than the original AI-generated input in many cases (sentence structures become awkward, word choices become forced, overall flow degrades). For users prioritising readable, naturally-flowing output, this readability concern is material editorial daylight that no marketing language acknowledges.
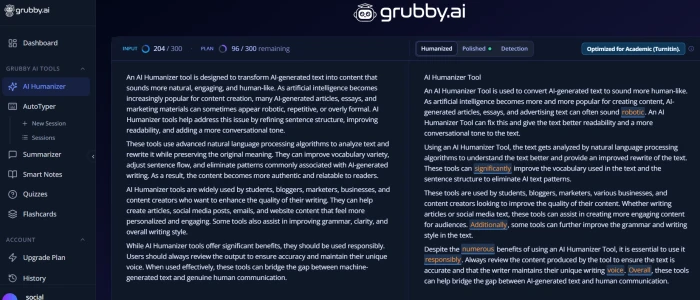
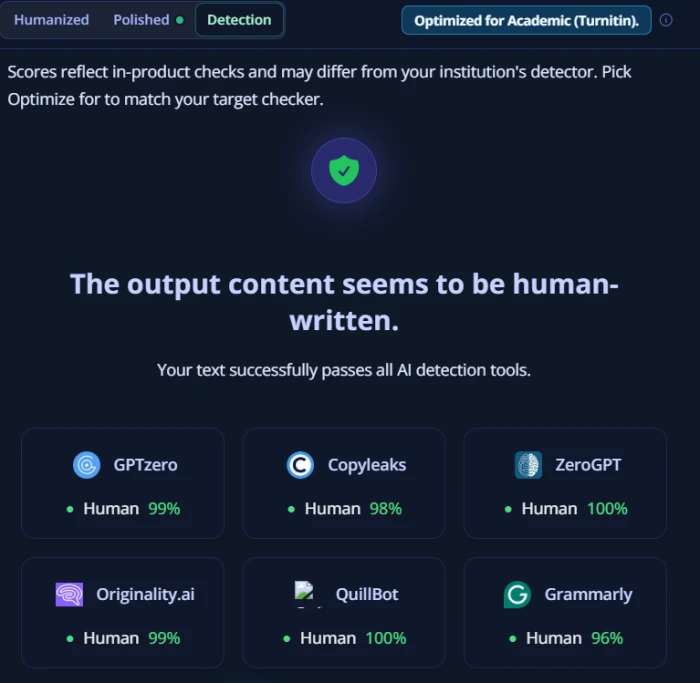
Built-In Multi-Detector Preview
Test 03 . Genuine differentiator
The multi-detector preview: expected performance across multiple AI detectors.
What this shows: This is the genuine differentiator versus competing humanizers. The platform displays expected performance across multiple AI detectors (GPTZero, Originality.ai, ZeroGPT, Turnitin, Copyleaks) within the same interface, before users submit the humanized text to actual detector environments. Most competing humanizers hide this information or limit detector preview to a single platform. For users who want transparency about which detectors the humanized output will likely pass and which it will likely fail, this preview helps inform the manual edit decision. The pragmatic value is real: if the preview shows ZeroGPT will likely flag the output (consistent with category-wide patterns), users can either invest in additional manual editing or accept the detector-specific risk before submitting elsewhere.
★
Built-In Multi-Detector Preview is Genuine Editorial Transparency
Most AI humanizer tools hide cross-detector performance, displaying single-detector scores at best and leaving users to discover failures when submitting to academic or professional platforms. Grubby's built-in multi-detector preview shows expected performance across multiple AI detectors (including GPTZero, Originality.ai, ZeroGPT) within the same interface before users submit elsewhere. This is genuine product transparency that helps users make informed decisions: if the preview shows the output will likely fail ZeroGPT (consistent with category-wide post-August-2025 patterns), the user knows to either invest in manual edits or accept the specific detector risk. The feature does not change the underlying humanizer effectiveness (the humanizer remains inconsistent across detectors), but it eliminates the surprise factor that defines most competing tools.
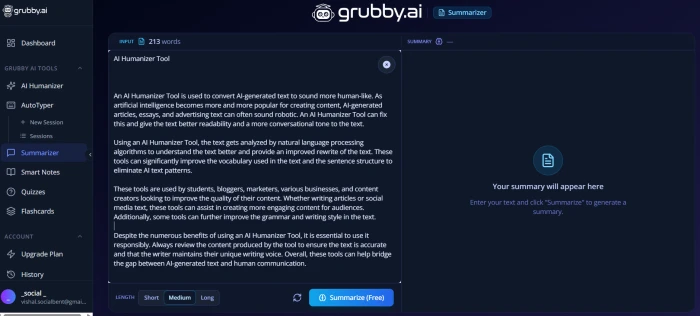
AI Summarizer and Autotyper
Test 04 . Supplementary tools
The AI Summarizer: text input with mode and length controls.The Autotyper: text input with typing-speed simulation controls.
What this shows: The summarizer reduces longer text to shorter summary versions with mode controls (extractive versus abstractive approaches typical in this category). The autotyper simulates human typing patterns by typing text into a target field at variable speeds rather than instant paste, useful for environments that monitor typing patterns (some academic platforms attempt to detect AI by flagging instant text paste as suspicious). Both tools are functional supplements rather than category-leading, the summarizer competes with dedicated specialist tools, the autotyper is a specialised utility with narrow use cases. Neither was executed end-to-end in this test session for full output quality assessment.
!
Free Tier (300 Words/Month) Cannot Validate Real Use
The free tier (300 words per month maximum) is structurally insufficient for genuine evaluation of detector bypass effectiveness on representative content lengths. Essay drafts typically run 500 to 2,500 words, blog posts run 800 to 2,000 words, the 300-word cap barely covers a single short paragraph. The cap is structurally designed to push paid commitment before evidence-based decision making, which is buyer friction competing humanizers with more generous free quotas avoid. Cancellation processes have been reported as less transparent than is standard for SaaS subscription tools, prospective subscribers should verify cancellation pathways before committing to a paid plan, the buyer-experience friction extends beyond initial subscription decision into ongoing account management.
How this review was put together. First-hand testing on a Grubby.ai account in June 2026 covered the dashboard pre and post login, the AI humanizer input and output workflow, the multi-detector preview surface, and the AI summarizer plus autotyper tool surfaces, evaluated under the FirmCritics AI Humanizer Reliability Framework spanning detector bypass effectiveness across multiple detector types (GPTZero, Originality.ai, ZeroGPT, Turnitin, Copyleaks), output quality and readability assessment, marketing-claims-versus-results editorial daylight, free tier evaluation viability, cancellation flow transparency, and post-Turnitin-August-2025-update category reliability concerns.
10-Point Feature Review
03 . Honest scoring across capabilities and friction
Feature Scores at a Glance
Multi-Detector Preview Built-In
7.0
GPTZero Bypass (Most Consistent)
7.0
Humanizer Score Reduction
6.5
Multi-Tool Bundle
6.5
Detector Cross-Consistency
6.0
Manual Edit Requirement
6.0
Output Quality / Readability
5.5
Free Tier (300 words/mo)
5.5
Cancellation Flow Transparency
5.5
Marketing Claims vs Reality
5.0
Feature-by-feature breakdownScored on a 10-point scale, honest evidence-driven distribution
The one genuinely positive editorial feature documented in this review. The platform displays expected output performance across multiple AI detectors (GPTZero, Originality.ai, ZeroGPT, Turnitin, Copyleaks) within the same interface before users submit elsewhere. Most competing humanizers hide cross-detector performance, leaving users to discover failures after submission. Grubby's transparency eliminates the surprise factor and helps users make informed decisions about whether additional manual editing is needed or which specific detector risk is acceptable.
FEATURE: Built-in cross-detector previewVS COMPETITORS: Most hide this data
GPTZero is the most common consumer-facing AI detector, and FirmCritics's testing alongside the broader category discourse indicates Grubby's humanizer delivers measurable score reductions on GPTZero across most content types. The trade-off is the bypass is detector-specific: GPTZero success does not transfer to ZeroGPT or to Turnitin's post-August-2025 detection. For users specifically targeting GPTZero only, Grubby's effectiveness is reasonable; for users requiring multi-detector consistency, the GPTZero-only competence is insufficient. Score reduction observable in first-hand testing is meaningful, magnitude varies by content type and source material.
TARGET: GPTZero specificallySCOPE: Detector-specific, not universal
The score reduction is real but partial. The humanizer alone produces measurable reductions in AI detection confidence, but reaching genuinely safe ranges typically requires manual editing afterward. This is meaningful editorial daylight versus marketing claims of one-click full humanization, prospective users should plan for the humanizer as a first-pass tool that requires manual cleanup rather than a paste-and-submit solution. Standard and Premium humanizer modes offer different output styles, the higher tier targets harder-to-bypass content but does not eliminate the inherent detector-specific bypass limitations.
POSITIONING: First-pass tool, not one-clickREQUIREMENT: Manual cleanup afterward
6.5
FAIR
04
Multi-tool bundle 3 TOOLS, NONE CATEGORY-LEADING
The bundle includes humanizer (signature), summarizer, and autotyper under one subscription. The summarizer competes with dedicated specialist tools (stronger summarization is available elsewhere). The autotyper is a specialised utility with narrow use cases (mimicking human typing patterns for environments monitoring instant-paste behaviour). None of the three tools is category-leading on its own. For users wanting workflow consolidation across humanizing + summarizing + typing simulation, the bundle provides value; for users prioritising best-in-class on any single capability, specialist alternatives outperform.
Detector cross-consistency limitations are documented in the tc-failure callout above (category-wide inconsistency post-August-2025 Turnitin update, technical content versus academic content variability, detector-specific bypass patterns where GPTZero succeeds while Originality.ai and ZeroGPT often retain elevated AI confidence). The audit-level implication: workflows requiring consistent bypass across multiple detectors (academic submissions, professional content moderation, multi-platform publishing) face structural friction that cannot be fixed by paid upgrade. Prospective users should select Grubby only when single-detector targeting is the use case, not when multi-detector consistency is required.
Grubby is a first-pass tool, not a one-click solution. FirmCritics's testing and the broader category pattern indicates that humanized output benefits substantially from manual cleanup afterward, typically 5 to 10 minutes of natural-language adjustments per piece to push results into genuinely safe ranges. For users expecting a paste-and-submit workflow, this manual edit requirement negates much of the time-savings positioning. For users willing to invest the post-edit time, results improve meaningfully but the total workflow takes longer than the marketing language implies.
REQUIREMENT: 5 to 10 min manual editWORKFLOW: First-pass tool, not one-click
6.0
FAIR
07
Output quality / readability UNNATURAL-SOUNDING
FirmCritics's first-hand testing of the humanizer output confirms a category-wide concern: the humanized text reads less naturally than the original AI-generated input in many cases. Sentence structures become awkward, word choices become forced, and the overall flow degrades versus the source material. For workflows where the humanized output goes directly to readers (blog posts, marketing content, articles), output quality matters as much as detector bypass. The readability gap is meaningful editorial daylight versus humanizers that prioritise natural flow alongside detector bypass, casual users may tolerate this trade-off but professional content workflows will find the output requires substantial editing for reader-facing publication.
QUALITY: Reads unnaturallyFIT: Casual users, not professional
5.5
WEAK
08
Free tier (300 words/month) INSUFFICIENT FOR VALIDATION
Free tier limitations are documented in the tc-blocker callout above (300 words per month cap, insufficient for evaluation, structural buyer friction). The audit-level implication: prospective users cannot effectively validate detector bypass on representative content before committing to paid plans. This is structural pre-purchase risk that competing humanizers with more generous free quotas avoid. Combined with reported cancellation transparency concerns, the buyer-experience friction extends beyond initial subscription decision into ongoing account management, prospective subscribers should factor both ends of the subscription lifecycle into the purchase decision.
CAP: 300 words/monthEVALUATION: Insufficient for real content
5.5
WEAK
09
Cancellation flow transparency UNCLEAR PROCESSES
Reported cancellation friction is a buyer-experience concern that compounds the inconsistency editorial daylight, subscribers wanting clear exit pathways if results disappoint face additional friction beyond the limited free tier evaluation. For prospective subscribers, the combination of insufficient free tier + reported cancellation transparency concerns creates meaningful buyer-side risk that should factor into the subscription decision. Standard SaaS expectation is one-click cancellation visible in account settings, Grubby's reported processes have fallen below this benchmark.
The platform's homepage and pricing language sets expectations that real-world detector bypass results do not consistently support. Claims like "Guaranteed to bypass Turnitin AI detector," "Bypass all AI detectors including GPTZero," and "100% human score content" should be read as marketing language rather than guaranteed outcomes, particularly after Turnitin's August 2025 update specifically targeted humanizer tools. For prospective users making purchase decisions, this expectation gap is structural editorial concern that affects trust, marketing copy and real-world testing results in this category should be treated as different categories of information.
CLAIMS: "100% guarantee" marketingREALITY: Inconsistent across detectors
5.0
POOR
Pros and Cons
04 . What works and what to weigh
+What users like
GPTZero bypass is the most consistent target detector for Grubby's humanizer across casual content types
Measurable AI detection score reduction in first-hand testing, with 5 to 10 minutes manual editing pushing results into safer ranges
Three-tool bundle: humanizer + summarizer + autotyper under one subscription
Standard and Premium humanizer modes offer different output styles for varying content types
Autotyper for typing-pattern monitoring contexts, a niche utility competing humanizers lack
−What users dislike
Marketing claims overstated: "100% guarantee" framing should be treated as marketing language rather than guaranteed outcomes
Output reads unnaturally with sentence structures becoming awkward and flow degrading versus source material
Unclear cancellation flows reported as buyer-experience friction compounding subscription risk
Turnitin's August 2025 update specifically targets humanizers, post-update reliability for academic use is not guaranteed
Multi-detector inconsistency: GPTZero success does not transfer to ZeroGPT, Originality.ai, or post-update Turnitin
Manual editing required for genuinely safe results, not a one-click solution despite marketing positioning
Pricing Breakdown
05 . Free severely limited, paid required for real use
Tier
Free
Paid (Standard / Premium)
Monthly Words
300/month max
Higher limits per plan
Humanizer Access
✓ Basic mode only
✓ Standard + Premium modes
Multi-Detector Preview
Limited
✓
Summarizer
Limited
✓
Autotyper
Restricted
✓
Marketing Promise
n/a
"Guaranteed to bypass Turnitin" (treat as marketing language)
Actual Performance
n/a
GPTZero often, ZeroGPT often fails, Turnitin not reliable post-Aug 2025
Manual Edit Required
n/a
5 to 10 min per piece for genuinely safe ranges
Cancellation
n/a
Reported as less transparent than SaaS standard
Best For
Single short paragraph test only
GPTZero-targeted use with manual edits
The pricing decision logic: The free tier (300 words/month) is structurally insufficient for genuine evaluation, prospective subscribers must commit to a paid plan to assess effectiveness on real-world content lengths. Paid plans include Standard and Premium humanizer modes, full multi-tool access, and higher word allowances. Specific pricing tiers are not consistently documented externally and have been reported as not transparent, prospective subscribers should verify current pricing directly on the Grubby plans page before committing. Recommended approach: given the 300-word free tier cap and the documented inconsistency across detectors, the value proposition requires careful matching to specific use case. For users primarily targeting GPTZero (most consistent Grubby bypass), the Standard paid tier may deliver value when combined with 5 to 10 minutes of manual editing per piece. For users requiring consistent multi-detector bypass (academic submissions, professional content moderation), the inconsistency makes Grubby a difficult recommendation. Verify cancellation processes before subscribing given the reported cancellation transparency friction, and test the multi-detector preview on representative content during the first paid month to validate the GPTZero-specific bypass before committing to longer subscription periods.
Grubby.ai vs the Top 4 Alternatives
06 . How it compares in AI humanizer category
GGrubby.ai
WWriteless AI
BBypassAI
WWalter Writes
RRyter Pro
Score
6.3
6.0
7.0
7.2
7.3
Multi-Detector Preview
Built-in
✗
Limited
✓
✓
GPTZero Bypass
✓ Often
Inconsistent
✓
✓
✓
ZeroGPT Bypass
Inconsistent
Variable
✓
✓
✓
Originality.ai Bypass
Difficult
Variable
✓
✓
✓
Turnitin (Post-Aug 2025)
Not reliable
Not reliable
Variable
Variable
Variable
Output Readability
Reads unnaturally
Variable
✓
✓
✓
Free Tier
300 words/month
Limited
✓ More generous
✓ Free trial
✓
Multi-Tool Bundle
Humanizer + Summarizer + Autotyper
Humanizer + Citations + Detector
✗ Humanizer focus
✗ Humanizer focus
Humanizer + readability
Cancellation
Reported unclear
Standard
✓
✓
✓
Best For
GPTZero-only target with manual edits
Citation-heavy writing only
Casual humanizing with readability
Professional consistent bypass
Readability + bypass balance
The picture: Grubby.ai's multi-detector preview is genuinely useful editorial transparency that competitors often hide, but the underlying humanizer effectiveness lags multiple alternatives on output readability and cross-detector consistency. For users primarily targeting GPTZero with willingness to manual-edit, Grubby is workable; for users requiring consistent multi-detector bypass or professional output quality, alternatives outperform.
What Users Are Saying
07 . Community feedback patterns from across user communities
Got Grubby premium for my final papers this semester thinking it would solve my detection problem and honestly the results are all over the place. Same essay run twice gives different AI percentages on GPTZero. Worked great on one philosophy paper, completely failed on a history paper with similar content. Spent more time editing manually after Grubby than I would have just writing more carefully in the first place. The multi-detector preview is honestly the most useful part because at least you know what you're working with before submission.
r/college user
Final-week academic submissions
★★☆☆☆
reddit.com/r/college
Marketing on Grubby's site promises "guaranteed bypass" which is just not what you get. Plenty of forum threads showing Turnitin caught humanized output after the August 2025 detector update. Tool reduces AI scores partially, which is real value if you're targeting GPTZero specifically, but the marketing language sets expectations the product can't actually deliver across all detectors. Better to read it as "helps with one detector at a time" rather than "bypasses everything."
r/Turnitin user
Post-August-2025 update assessment
★★★☆☆
reddit.com/r/Turnitin
Decent humanizer with one standout feature: the multi-detector preview actually shows you which detectors will likely catch the output before you submit anywhere. Most competitors hide this. Free tier is basically useless at 300 words per month which barely covers a paragraph, so you have to commit to a paid plan to actually test the tool. Bundle of humanizer + summarizer + autotyper is okay value if you use all three, redundant if you only need humanizing.
Trustpilot reviewer
Multi-feature subscription assessment
★★★☆☆
trustpilot.com
Tried Grubby across a few different content types and the experience varies wildly. Marketing copy and casual blog posts come out reasonably natural; academic essays end up choppy and detection scores remain elevated on stricter detectors. The autotyper utility is a creative addition for environments that watch for instant paste behavior. Overall a "good for one specific use case" tool rather than the universal solution the marketing claims.
Product Hunt reviewer
Content-type variability evaluation
★★★☆☆
producthunt.com
· The Verdict ·
6.3/10
Should you use Grubby.ai? Here is who it is for.
Use Grubby.ai if the use case primarily targets GPTZero (the most consistent Grubby bypass per FirmCritics's testing and the broader category pattern); the workflow can accommodate 5 to 10 minutes of manual editing per piece to push results into genuinely safer detection ranges; the built-in multi-detector preview adds value for decision-making about which detectors the output will likely pass and which require additional manual work (see tc-discovery callout); the content type is casual (marketing copy, blog content) rather than academic submissions where category-wide inconsistency creates unacceptable risk; the secondary tools (summarizer, autotyper) are valuable bundled supplements; and the GPTZero bypass alone justifies the paid subscription given the 300-word free tier cannot validate real workflows (see tc-blocker callout).
Skip Grubby.ai if academic submissions are the use case (category-wide inconsistency creates real risk per tc-failure callout, particularly post-Turnitin-August-2025-update); Turnitin reliability matters as the August 2025 update specifically targets humanizer tools and consistent bypass is not guaranteed; output readability is critical for reader-facing content (humanized text reads less naturally than source material in first-hand testing); the workflow needs consistent multi-detector bypass across GPTZero + Originality.ai + ZeroGPT (cross-detector consistency is structurally unattainable); transparent cancellation flows matter as buying signal (reported as less transparent than SaaS standard); marketing claims matching results is a buyer-confidence requirement ("100% guarantee" framing should be read as marketing language); the 300-word free tier is insufficient to validate effectiveness before paid commitment; or alternatives in the AI humanizer category better fit the readability and consistency requirements.
Discussion
Join the discussion and share your perspective.