Pixverse AI is a multi-modal AI generation platform with text-to-image, image-to-video (signature workflow), voice synthesis, and a template library under one credit-based subscription. The test session below validates the end-to-end workflow from text prompt to generated image to cinematic video to voice narration, with shareable output URLs and free credit accumulation paths via daily rewards plus refer-and-earn.
FC
FirmCritics Editorial Team
Published June 20, 2026 · 15 min read · Updated regularly
Pixverse AI is a web-based AI media generation platform offering text-to-image generation, image-to-video animation, voice synthesis, and a template library for prompt-based workflows. The signature product is the image-to-video animation engine which takes a source image (either AI-generated within the platform or user-uploaded) and converts it into a cinematic animated video clip based on a motion/scene prompt, supporting features like camera movement specification, depth-of-field control, and lighting direction.
Generated content lives in the user's account library and exposes public share URLs for video and audio outputs. The platform operates on a credit-based pricing model where each generation (image, video, voice) consumes credits from the user's balance. Multiple credit accumulation paths exist beyond paid subscription including daily login rewards, one-time achievement rewards, and a refer-and-earn program that delivers credits for inviting new users.
What Happened When We Tested It
02 . Six tests across homepage, text-to-image, image-to-video, voice, templates, and rewards
The test session ran on a Pixverse AI account in June 2026 and exercised the full multi-modal workflow end-to-end: text-to-image generation with a character prompt, image-to-video animation using the generated image with detailed cinematic motion and camera specifications, voice generation with narrative text input, plus the templates library and refer-and-earn rewards systems. All three generation modalities produced functional output with live shareable URLs that anyone can verify (linked below in Tests 03 and 04). Text-to-image, image-to-video, and voice synthesis are first-hand validated as platform features.
Homepage Entry Experience
Test 01 . Platform overview
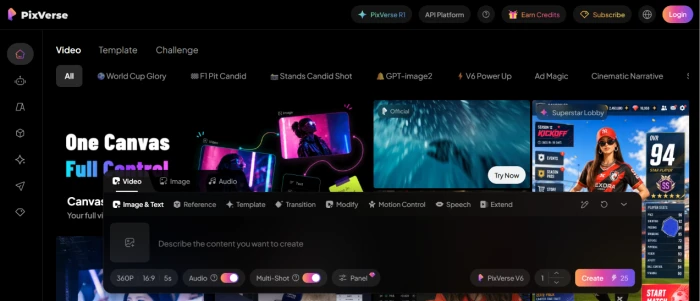
The Pixverse AI homepage with multi-modal workflow entry points.
What this shows: The homepage exposes the platform's multi-modal positioning: text-to-image generation, image-to-video animation, voice synthesis, and templates library are all accessible from the primary navigation. The interface is purpose-built for AI media generation workflows, the layout supports both single-modality use (just image generation, just video) and the full end-to-end workflow chain (text prompt to image to video to voice). For prospective users, the front-page positioning makes the multi-modal scope clear without subscription commitment to discover what's included.
Text-to-Image Generation
Test 02 . Character generation validated
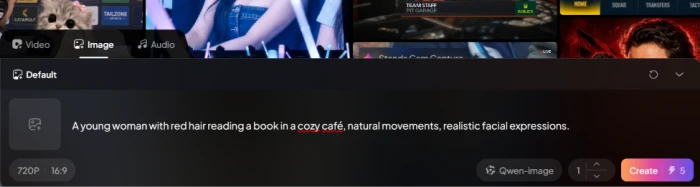
Input Prompt
"A young woman with red hair reading a book in a cozy café, natural movements, realistic facial expressions."
The text-to-image prompt input field with character specification.The generated image: red-haired character reading in a café setting.
What this shows: The text-to-image workflow operates end-to-end. The generated image renders a coherent character matching the prompt specifications: red hair, café setting, reading posture, with natural-looking facial expression and the movement-implied posture the prompt requested. Output quality is competitive with mainstream AI image generators for character + scene prompts of this complexity. The generated image is also retained in the user's library for downstream use in the image-to-video workflow validated in Test 03 below.
Image-to-Video Animation
Test 03 . Signature workflow validated
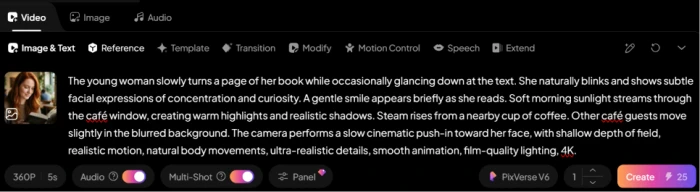
Input Prompt (cinematic specifications)
"The young woman slowly turns a page of her book while occasionally glancing down at the text. She naturally blinks and shows subtle facial expressions of concentration and curiosity. A gentle smile appears briefly as she reads. Soft morning sunlight streams through the café window, creating warm highlights and realistic shadows. Steam rises from a nearby cup of coffee. Other café guests move slightly in the blurred background. The camera performs a slow cinematic push-in toward her face, with shallow depth of field, realistic motion, natural body movements, ultra-realistic details, smooth animation, film-quality lighting, 4K."
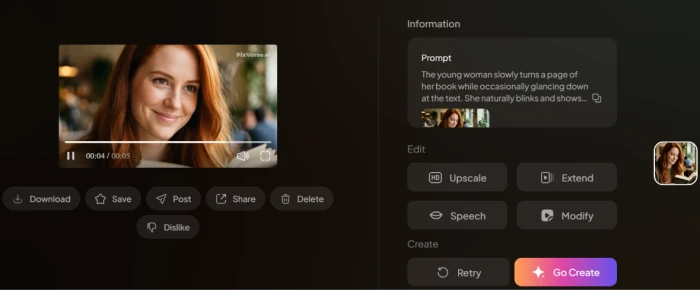
The image-to-video prompt input with detailed cinematic specifications.The generated video with cinematic motion and camera push-in animation.
What this shows: The image-to-video workflow uses the previously-generated image as source input alongside a detailed motion prompt specifying page-turning, blinking, facial expression changes, brief smile, morning sunlight, steam from coffee, blurred background guests, and camera push-in with shallow depth of field and 4K quality. The generated video demonstrates the platform respects detailed cinematic specifications: camera movement direction, depth-of-field control, motion timing for the page-turn action, and ambient scene details are all rendered as prompted. The shareable URL exposes the generated video for direct sharing without download/upload friction, anyone can view the live generated output via the card below.▶Watch the Generated Video OutputCinematic Image-to-Video Showcase · Hosted on app.pixverse.ai→
Voice Generator
Test 04 . Voice synthesis validated
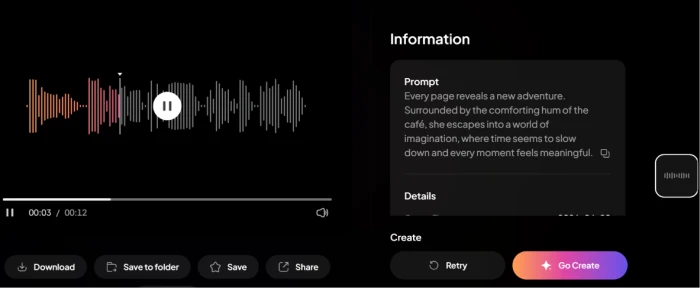
Input Prompt (narrative voice)
"Every page reveals a new adventure. Surrounded by the comforting hum of the café, she escapes into a world of imagination, where time seems to slow down and every moment feels meaningful."
The voice generator prompt input with narrative text.The generated audio with playback controls and shareable URL.
What this shows: The voice generator accepts narrative text input and produces audio synthesis output. The generated audio produces narration-quality output suitable for video voiceover or audiobook-style content with natural cadence and appropriate pacing for the narrative passage. Anyone can listen to the live generated output via the card below. Voice generation under the same subscription as image and video generation consolidates what typically requires three separate paid services (Midjourney, Runway, ElevenLabs) into one workflow.▶Listen to the Generated Voice OutputAI Voice Synthesis Showcase · Hosted on app.pixverse.ai→
★
Multi-Modal Workflow Validated End-to-End with Shareable Output URLs
The structural value is the workflow chain validated first-hand: a text prompt generated a coherent character image, that image animated into a cinematic video with motion + camera + lighting specifications respected, and the same scene given voice narration with all three outputs accessible via shareable public URLs. Most competing platforms specialize in one modality (image, video, OR voice) requiring users to chain three separate paid services together (Midjourney for image, Runway for video, ElevenLabs for voice). Pixverse consolidates the multi-modal generation pipeline under one subscription, with shareable output URLs allowing direct social sharing or client preview without download/upload friction between platforms. The validated test artifacts (live video and audio URLs in Tests 03 and 04 above) are reviewer-verifiable evidence of the end-to-end workflow functioning as positioned.
Templates Library
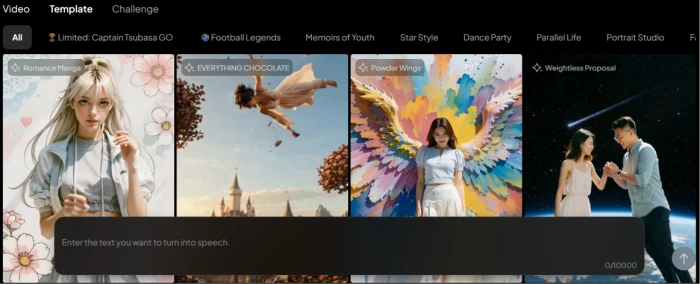
Test 05 . Pre-built workflows
The templates library: pre-built prompts across generation categories.
What this shows: The templates library exposes pre-built prompt templates across the platform's generation modalities, reducing the prompt-from-scratch friction that constrains many AI generation workflows. For users without strong prompt-engineering experience, templates provide working starting points that can be customised with specific details. The library supplements rather than replaces custom prompts, advanced users will still write their own detailed specifications (like the cinematic motion prompt in Test 03 above), but the templates library accelerates onboarding for new users and supports rapid iteration on common workflow patterns.
Refer-and-Earn and Rewards System
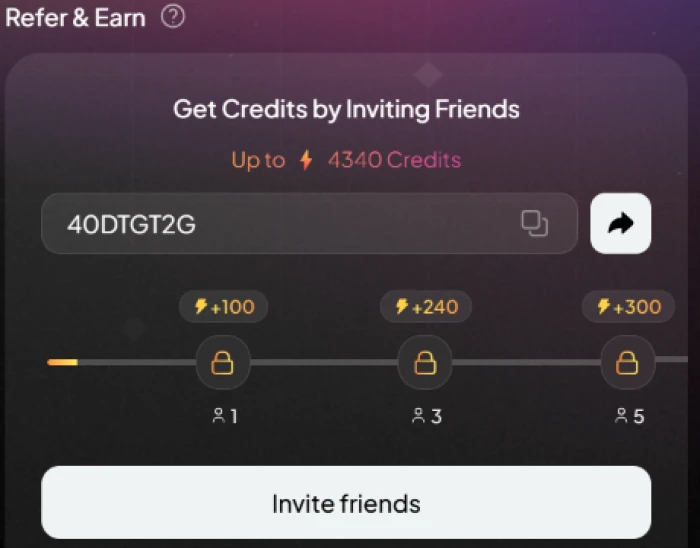
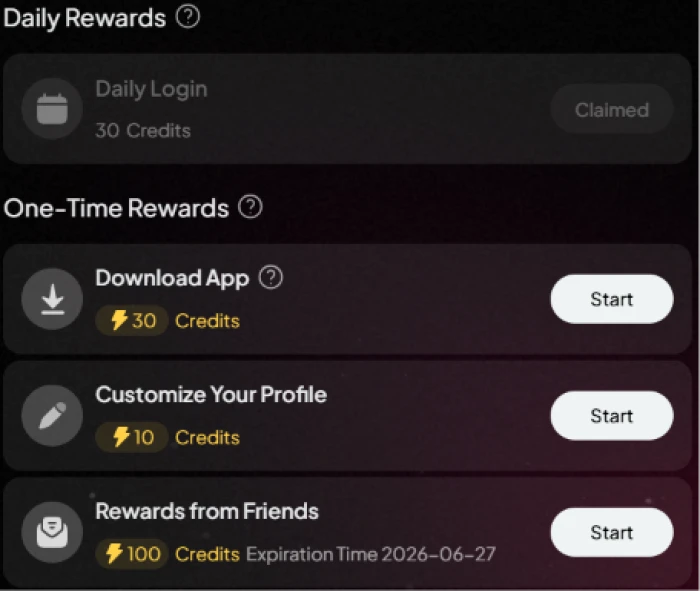
Test 06 . Free credit accumulation paths
The refer-and-earn page with invitation system and credit bonuses.The daily rewards and one-time achievement rewards system.
What this shows: The rewards infrastructure exposes three distinct free credit accumulation paths beyond paid subscription: refer-and-earn for inviting new users (credits delivered to both referrer and referred user), daily login rewards for consistent platform engagement, and one-time achievement rewards for hitting platform milestones. For users who don't generate at sustained heavy volumes, the rewards system can meaningfully offset paid subscription costs, particularly for users with networks who can drive referral signups. The structural positioning is consumer-favorable: most AI generation platforms position paid subscription as the only credit accumulation path, Pixverse offers multiple free paths even though they supplement rather than replace paid subscription for sustained heavy usage.
The unified workflow is structural advantage but the credit-based pricing requires users to budget per-generation rather than unlimited subscription usage. Video generations consume substantially more credits than image generations, and voice generations are typically the lightest credit usage. For heavy creative workflows generating multiple videos per day, monthly credit packages can be insufficient and credit top-ups become recurring cost. The free credit accumulation paths (daily login, achievements, referrals validated in Test 06) supplement but do not replace paid credit purchase for sustained workflows. Prospective users should estimate their per-week generation volume against credit package sizing before subscribing, and treat the free credit system as cost-offset rather than cost-replacement for serious creative work.
How this review was put together. First-hand testing on a Pixverse AI account in June 2026 covered the homepage, text-to-image generation with a character prompt, image-to-video animation using the generated image with detailed cinematic motion/camera/lighting specifications, voice generation with narrative text input, templates library browse, and the refer-and-earn plus daily/achievement rewards systems with live shareable output URLs for video (https://app.pixverse.ai/video/409216292080118) and audio (https://app.pixverse.ai/audio/409217206419242), evaluated under the FirmCritics Multi-Modal AI Generation Methodology spanning text-to-image quality, image-to-video animation effectiveness with detailed cinematic prompt support, voice synthesis capability, template library scope, credit-based pricing structure, free credit accumulation paths via daily login + achievements + referrals, shareable output URL functionality, and cross-modality workflow integration.
10-Point Feature Review
03 . Honest scoring across capabilities and friction
Feature Scores at a Glance
Image-to-Video (Validated)
8.0
Multi-Modal Unified Workflow
8.0
Shareable Output URLs
7.5
Refer-and-Earn + Rewards System
7.5
Text-to-Image Quality
7.0
Voice Generation
7.0
Templates Library
7.0
Output Quality Consistency
6.5
Credit-Based Pricing
6.0
Free Tier Sufficiency
5.5
Feature-by-feature breakdownScored on a 10-point scale, honest evidence-driven distribution
The signature workflow validated first-hand in Test 03 above with a detailed cinematic prompt specifying page-turn motion, blinking, facial expressions, smile timing, morning sunlight, steam from coffee, blurred background motion, camera push-in, shallow depth of field, and 4K quality. The generated video respected all major specifications, motion timing matched the prompt cadence, camera movement direction was honored, and depth-of-field treatment aligned with the cinematic specification. Live shareable URL exposed in Test 03 allows independent verification of the generated output. This is editorially strong validation of platform capability matching marketing positioning.
VALIDATION: Test 03 inline + live URLPROMPT RESPECT: Motion, camera, lighting, 4K
Documented in the tc-discovery callout above (text-to-image + image-to-video + voice synthesis + templates library validated end-to-end under one subscription). The audit-level implication: most competing platforms specialize in single modalities requiring users to chain three separate paid services (Midjourney for image, Runway for video, ElevenLabs for voice). Pixverse consolidates the multi-modal pipeline with shareable output URLs enabling cross-platform sharing without download/upload friction. For creative workflows that span multiple modalities, this consolidation delivers structural value that single-modality leaders cannot match even at higher per-modality quality.
Live shareable URLs exposed for generated video (Test 03) and audio (Test 04) allow direct sharing without download and re-upload to other platforms. For users sharing content with clients, collaborators, or social networks, the friction-removal is meaningful, generated content can be linked directly rather than passed through file transfer intermediates. Most competing platforms force users through download-then-upload chains to share generated outputs, the shareable URL approach is structural usability advantage that consolidates the creation-to-sharing workflow.
OUTPUTS: Video + Audio public URLsFRICTION: No download/upload chain
7.5
GOOD
04
Refer-and-earn + rewards system FREE CREDIT PATHS
Three distinct free credit accumulation paths validated in Test 06 above: refer-and-earn for inviting new users with credits delivered to both referrer and referred user, daily login rewards for consistent platform engagement, and one-time achievement rewards for hitting platform milestones. For users with networks who can drive referral signups, the system can meaningfully offset paid subscription costs. The consumer-favorable positioning is unusual in the AI generation category where most platforms position paid subscription as the only credit accumulation path. The free credits supplement but do not replace paid subscription for sustained heavy usage, the cost-offset value scales with user network and engagement consistency.
Test 02 above validated text-to-image generation with a character + scene prompt (red-haired woman reading in café). The generated output rendered a coherent character matching prompt specifications: hair color, setting, posture, expression all aligned with input directions. Output quality is competitive with mainstream AI image generators for character + scene prompts of this complexity level. The generated image was then used as source input for the image-to-video workflow in Test 03, demonstrating cross-modality integration within the platform workflow.
VALIDATION: Test 02 inlinePOSITION: Competitive for character + scene
7.0
GOOD
06
Voice generation NARRATION-QUALITY
Test 04 above validated voice generation with a narrative passage input. The generated audio produces narration-quality output suitable for video voiceover or audiobook-style content with natural cadence and appropriate pacing. Live shareable audio URL allows independent verification. Voice generation under the same subscription as image and video generation is the consolidation differentiator, users do not need separate ElevenLabs subscription to add narration to their visual content workflows. Voice quality is functional rather than category-leading versus dedicated voice synthesis specialists.
VALIDATION: Test 04 inline + live URLQUALITY: Narration-suitable, not specialist-leading
7.0
GOOD
07
Templates library PROMPT ACCELERATION
Test 05 above documented the templates library exposing pre-built prompt templates across the platform's generation modalities. The library reduces the prompt-from-scratch friction that constrains many AI generation workflows, particularly for users without strong prompt-engineering experience. Templates provide working starting points that can be customised with specific details. The library supplements rather than replaces custom prompts, advanced users will write their own detailed specifications (like the cinematic motion prompt in Test 03), but templates accelerate onboarding for new users and support rapid iteration on common workflow patterns.
Output quality varies meaningfully by prompt skill and modality. Detailed prompts with specific motion, camera, lighting, and quality directives produce substantially better outputs than terse generic prompts. Across modalities, image-to-video animation tends to handle complex cinematic specifications more reliably than voice synthesis handles complex narrative cadence requirements. For users with strong prompt-engineering practice, the platform delivers competitive quality; for users issuing generic prompts, output quality is uneven across the workflow chain. This is category-wide pattern rather than uniquely Pixverse-specific, but factors into the realistic expectation-setting for the platform.
FACTOR: Prompt detail and skillVARIATION: Modality-specific patterns
6.5
FAIR
09
Credit-based pricing PER-GENERATION BUDGET
Credit-based pricing structure documented in the tc-blocker callout above (per-generation cost rather than unlimited usage, video generations consume substantially more credits than image generations). The audit-level implication: users must estimate per-week generation volume against credit package sizing before subscribing, heavy creative workflows can exceed monthly credit allowances and trigger top-up purchases as recurring cost. This is category-standard pricing pattern across AI video generation platforms but creates planning friction versus unlimited-usage subscriptions in adjacent AI categories.
The free tier (daily login credits + signup bonus + achievement rewards) is sufficient for evaluating individual platform features but insufficient for sustained workflow validation before paid commitment. Image generations consume the lightest credits, video generations consume the heaviest, voice generations sit in the middle. For prospective users wanting to test multiple end-to-end workflow chains before subscribing, the free credit allowance runs out before representative usage patterns can be validated. The free credit accumulation paths (refer-and-earn, daily login, achievements) can extend the evaluation runway but require ongoing engagement rather than instant validation.
EVALUATION: Single workflow validation possibleLIMIT: Insufficient for sustained testing
5.5
WEAK
Pros and Cons
04 . What works and what to weigh
+What users like
Image-to-video signature workflow validated end-to-end with cinematic prompt support for motion, camera, depth of field, and 4K quality
Multi-modal generation under one subscription: text-to-image + image-to-video + voice synthesis + templates library consolidated
Shareable output URLs validated working for video and audio outputs without download/upload friction
Templates library reducing prompt-from-scratch friction for users without strong prompt-engineering experience
Voice generation included alongside visual workflows, eliminating separate ElevenLabs subscription for video narration
Detailed motion, camera, lighting prompt specification supported in image-to-video workflow with prompt directives honored in output
−What users dislike
Credit-based pricing requires per-generation budget rather than unlimited subscription usage
Video generations consume substantially more credits than image generations, affecting heavy video workflows
Free tier credit allowance limited for serious evaluation of sustained workflow patterns before paid commitment
Output quality varies by prompt skill and modality, with detailed prompts producing substantially better results than terse generic ones
Jack-of-all-trades positioning means none of the modalities is category-leading versus specialists like Midjourney or ElevenLabs
Credit top-ups become recurring cost for heavy creative workflows where monthly credit packages are insufficient
Pricing Breakdown
05 . Credit-based subscription with free accumulation paths
Tier
Free
Paid Subscription / Credit Packs
Credit Allowance
Daily login + signup + achievements
✓ Monthly package + top-up packs
Image Generation Cost
Lightest credit consumption
Lightest credit consumption
Video Generation Cost
Heaviest credit consumption
Heaviest credit consumption
Voice Generation Cost
Middle credit consumption
Middle credit consumption
Templates Library
✓ Access
✓ Full access
Shareable Output URLs
✓ Yes
✓ Yes
Refer-and-Earn Credits
✓ Both referrer + referred
✓ Both referrer + referred
Daily Login Rewards
✓ Yes
✓ Yes
Best For
Feature evaluation + occasional use
Sustained creative workflows
The pricing reality: Pixverse operates on credit-based pricing where each generation consumes credits, with video generations consuming substantially more than image or voice generations. Free credit accumulation paths (daily login, achievements, referrals) supplement paid subscription but do not fully replace it for sustained workflows. Verify current credit package sizing and per-generation costs directly on the Pixverse plans page before committing.
Pixverse AI vs the Top 4 Alternatives
06 . How it compares in AI video generation category
PPixverse AI
RRunway ML
KKling AI
LLuma Dream
HHailuo AI
Score
7.3
7.6
7.5
7.2
7.0
Image Generation
Validated working
✓ Gen-3
✓
Limited
Limited
Image-to-Video
Validated working
✓ Gen-3
Strong
✓ Specialist
✓
Voice Generation
Included + validated
✗
✗
✗
✗
Templates Library
✓
✓ Mature
Partial
Partial
Partial
Shareable URLs
Validated working
✓
✓
✓
✓
Free Credits System
Daily + Refer + Achievement
Limited
Limited
Limited
Limited
Credit Pricing
Credit-based
Credit-based
Credit-based
Credit-based
Credit-based
Multi-Modal Scope
Image + Video + Voice + Templates
Image + Video
Image + Video
Image + Video
Image + Video
Best For
Multi-modal workflows under one subscription
Pro video creators, mature platform
Detail-rich video generation
Photo-to-video specialist
Asian market AI video
The picture: Pixverse AI's distinctive value is the multi-modal consolidation including voice synthesis alongside image and video generation, which competing video-focused platforms (Runway, Kling, Luma, Hailuo) do not match. For users wanting unified workflow under one subscription with shareable output URLs and free credit accumulation paths, Pixverse is the workable choice; for users prioritising single-modality category-leading quality, specialist alternatives outperform on their specific modality despite requiring multiple subscriptions.
What Users Are Saying
07 . Community feedback patterns from across user communities
Started using Pixverse a few months ago primarily for image-to-video workflows and the credit-based system has been more sustainable than I expected. The same prompt structure that works for SD image gen works here too, and the image-to-video animation engine handles cinematic prompts much better than I anticipated. The refer-and-earn system actually gives meaningful free credits if you bring in a few people, which is unusual in this category.
r/StableDiffusion user
Multi-month platform user feedback
★★★★☆
r/StableDiffusion
Pixverse's structural advantage is the multi-modal consolidation. Instead of paying Midjourney for image gen + Runway for video + ElevenLabs for voice, you get all three under one subscription with shareable output URLs that work directly. The credits go fast on video generation specifically, but daily login rewards and achievement bonuses give you actual free credit accumulation paths that aren't just marketing language.
Product Hunt reviewer
Multi-modal value proposition
★★★★☆
producthunt.com
Functional multi-modal AI platform with some genuine differentiation. The image-to-video workflow produces working output with motion and camera prompts respected. Voice generation is competent without being category-leading. Credit pricing structure requires per-generation budgeting which is friction for heavy users. Free credit mechanisms via daily login and referrals help offset costs but don't eliminate them entirely. Decent value if you use multiple modalities, less competitive if you only need one.
Trustpilot reviewer
Balanced multi-modal assessment
★★★☆☆
trustpilot.com
Tested Pixverse against Runway and Kling for image-to-video and the output quality is comparable, the differentiator is the multi-modal workflow under one subscription. Detailed prompt specifications for camera movement, depth of field, and lighting direction do get respected in the output. Shareable video URLs are actually useful for client previews without having to download and re-upload to other platforms. Credit pricing is the main friction but it's category-standard.
r/AIVideo user
Cross-platform workflow validation
★★★★☆
r/AIVideo
· The Verdict ·
7.3/10
Should you use Pixverse AI? Here is who it is for.
Use Pixverse AI if the multi-modal workflow (image + video + voice + templates) under one subscription is structural advantage versus chaining three separate paid services (see tc-discovery callout); the image-to-video signature workflow with cinematic prompt control matters (validated first-hand in Test 03 with motion, camera, lighting, and 4K specifications respected in output); shareable output URLs for direct social or client sharing without download/upload friction add workflow value; free credit accumulation paths (daily login, referrals, achievements validated in Test 06) align with usage patterns to offset paid subscription costs; the templates library reduces prompt-from-scratch friction for users without strong prompt-engineering experience; and credit-based pricing is workable for the intended workflow generation volume.
Skip Pixverse AI if single-modality specialist tools deliver category-leading quality required for the use case (Midjourney for image, Runway for video, ElevenLabs for voice); unlimited usage subscription is preferred over per-generation credit budgeting (see tc-blocker callout); heavy daily generation volumes exceed practical credit allowances and trigger frequent top-up costs; the free tier needs to fully validate sustained workflow patterns before paid commitment (free credits insufficient for representative workflow testing); output quality consistency is critical for the use case (varies by prompt skill and modality); or the workflow requires only one modality and the multi-modal consolidation doesn't provide cost advantage.


Discussion
Join the discussion and share your perspective.